

 Tóm tắt: Một trong những hiểu lầm phổ biến trong diễn giải kết quả nghiên cứu lâm sàng là nhầm lẫn giữa odds ratio (OR) và relative risk (RR). Nhiều công trình nghiên cứu lâm sàng đối chứng ngẫu nhiên (randomized controlled trial – RCT)
Tóm tắt: Một trong những hiểu lầm phổ biến trong diễn giải kết quả nghiên cứu lâm sàng là nhầm lẫn giữa odds ratio (OR) và relative risk (RR). Nhiều công trình nghiên cứu lâm sàng đối chứng ngẫu nhiên (randomized controlled trial – RCT)
Giáo sư y khoa, Đại học New South Wales
Viện nghiên cứu y khoa Garvan, Sydney, Australia
Tóm tắt: Một trong những hiểu lầm phổ biến trong diễn giải kết quả nghiên cứu lâm sàng là nhầm lẫn giữa odds ratio (OR) và relative risk (RR). Nhiều công trình nghiên cứu lâm sàng đối chứng ngẫu nhiên (randomized controlled trial – RCT) thường có xu hướng báo cáo kết quả qua chỉ số RR, nhưng cũng có khi OR được sử dụng để mô tả ảnh hưởng của một thuật điều trị hay mối liên hệ giữa hai yếu tố. Sự lựa chọn này dẫn đến hiểu lầm rằng hai chỉ số này giống nhau, và sự hiểu lầm xảy ra ở ngay cả những nhà nghiên cứu có kinh nghiệm. Tuy nhiên, OR không có cùng ý nghĩa với RR. Nói ngắn gọn, OR là một ước số của RR. Trong điều kiện tần số mắc bệnh thấp hay rất thấp (dưới 1%) thì OR và RR tương đương nhau, nhưng khi tần số mắc bệnh cao hơn 20% thì OR có xu hướng ước tính RR cao hơn thực tế. Bài này sẽ giải thích những khác biệt quan trọng giữa 2 chỉ số này, và trình bày một cách diễn giải đúng hơn.
Trong một bài báo khoa học về mối liên hệ giữa gene RUNX2 và gãy xương, các tác giả viết: “The risk of fracture in the CC genotype was 45% lower than TT group (OR = 0.55; 95% CI: 0.32 – 0.94; P = 0.03)“. Tuy nhiên cách diễn giải này sai, vì tác giả hiểu lầm khái niệm risk và odds. Thật ra, đây là một hiểu lầm rất phổ biến, vì các nhà nghiên cứu thường hiểu OR tương đương với RR, nhưng hai chỉ số này khác nhau.
Prevalence và incidence
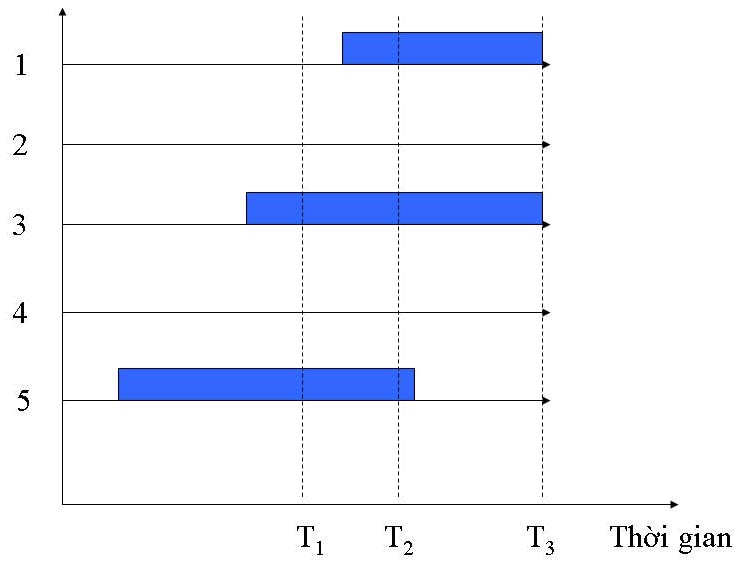
Trước khi phân biệt khái niệm risk và odds, chúng ta cần phân biệt hai chỉ số thông dụng trong nghiên cứu lâm sàng và dịch tễ học: tỉ lệ lưu hành (prevalence) và tỉ lệ phát sinh (incidence). Tỉ lệ lưu hành, như tên gọi, là tỉ lệ ca bệnh hiện lưu hành trong một quần thể ngay tại một thời điểm. Tỉ lệ lưu hành phản ảnh qui mô của một vấn đề y tế, nhưng không cho chúng ta biết về bệnh căn học (etiology). Tỉ lệ phát sinh, có khi được đề cập đến như là tỉ lệ tấn công (attack rate), là tỉ lệ số ca mới mắc bệnh trong một thời gian theo dõi. Tỉ lệ phát sinh có giá trị khoa học là nó cung cấp cho chúng ta một vài thông tin về bệnh căn học. Chẳng hạn như một quần thể gồm 5 cá nhân (kí hiệu 1, 2, 3, …, 5 trong biểu đồ dưới đây), với 3 người mắc bệnh (đối tượng 1, 3 và 5).
Nếu một nghiên cứu cắt ngang được thực hiện tại thời điểm T1 thì tỉ lệ lưu hành ước tính lúc đó là 2/5 = 30%. Nhưng nếu công trình nghiên cứu thực hiện tại thời điểm T2 thì tỉ lệ lưu hành là 3/5 = 60%. Nếu công trình nghiên cứu theo dõi 5 cá nhân đến thời điểm T3, và trong thời gian này có 3 cá nhân mắc bệnh; do đó, tỉ lệ phát sinh trong thời gian này là 3/5 = 60%.
Khái niệm nguy cơ (risk) và odds
Trong y khoa, nguy cơ mắc bệnh thực chất là xác suất. Xác suất, như chúng ta biết, là một biến số giữa 0 và 1. Xác suất thực chất là tỉ lệ, tỉ số, và phần trăm. Do đó, thuật ngữ risk trong y khoa có thể có nghĩa là xác suất, tỉ lệ lưu hành, hay tỉ lệ phát sinh.
Cụm từ nguy cơ, dịch từ chữ risk trong tiếng Anh, có rất nhiều nghĩa trong y khoa. Cần phải phân biệt nguy cơ mắc bệnh và bệnh. Khi nói đến ung thư, chúng ta muốn nói đến một sự kiện cho một cá nhân; nhưng khi nói đến nguy cơ ung thư hay cancer risk, chúng ta nói đến nguy cơ xảy ra, nguy cơ phát sinh cho một cá nhân hay một quần thể. Xin nhắc lại, sự kiện khác với nguy cơ sự kiện. Do đó, ung thư khác với nguy cơ ung thư, vì ung thư là một sự kiện mang tính khẳng định (certainty), còn nguy cơ ung thư là một biến số liên tục mang tính bất định (uncertainty). Tất cả chúng ta trong bất cứ thời điểm nào đều có nguy cơ bị bệnh; nhưng có người có nguy cơ cao, có người có nguy cơ thấp.
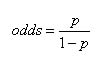
Ví dụ: nếu nguy cơ bệnh nhân bị ung thư trong vòng 5 năm tới là 0.10 (tức 10%) thì odds mà bệnh nhân bị ung thư là 0.1/ (1 – 0.1) = 0.11. Theo định nghĩa này odds không phải là nguy cơ hay risk.
OR và RR: cơ chế tính toán
OR và RR là hai chỉ số thống kê rất phổ biến và có ích trong nghiên cứu lâm sàng, vì cả hai chỉ số kiểm định mối liên hệ giữa một yếu tố nguy cơ và bệnh tật – một mục tiêu gần như căn bản của nghiên cứu y học hiện đại. Cơ chế tính toán của hai chỉ số này cực kì đơn giản.
Hãy tưởng tượng một công trình nghiên cứu RCT với 2 nhóm: nhóm được điều trị tích cực với một loại thuốc gồm n1 bệnh nhân, và một nhóm chứng (placebo) gồm n2 bệnh nhân. Sau một thời gian điều trị, có k1 bệnh nhân trong nhóm được điều trị mắc bệnh, và k2 bệnh nhân trong nhóm chứng mắc bệnh. Như vậy, tỉ lệ mắc bệnh của nhóm điều trị (kí hiệu p1
) và nhóm chứng (p2) được ước tính như sau:

Nếu RR > 1 (hay p1 > p2 ![]() ), chúng ta có thể phát biểu rằng yếu tố nguy cơ làm tăng khả năng mắc bệnh; nếu RR = 1 (tức là p1 = p2
), chúng ta có thể phát biểu rằng yếu tố nguy cơ làm tăng khả năng mắc bệnh; nếu RR = 1 (tức là p1 = p2 ![]() ), chúng ta có thể nói rằng không có mối liên hệ nào giữa yếu tố nguy cơ và khả năng mắc bệnh; và nếu RR < 1 (tức
), chúng ta có thể nói rằng không có mối liên hệ nào giữa yếu tố nguy cơ và khả năng mắc bệnh; và nếu RR < 1 (tức ![]() p1 < p2), chúng ta có bằng chứng để thể phát biểu rằng yếu tố nguy cơ có thể làm giảm khả năng mắc bệnh.
p1 < p2), chúng ta có bằng chứng để thể phát biểu rằng yếu tố nguy cơ có thể làm giảm khả năng mắc bệnh.
Odds ratio: Thay vì sử dụng tỉ lệ phát sinh p để đo lường khả năng mắc bệnh, thống kê cung cấp cho chúng ta một chỉ số khác: đó là odds. Odds như đề cập trên là tỉ số của hai xác suất. Nếu p là xác suất mắc bệnh, thì 1 – p là xác suất sự kiện không mắc bệnh. Theo đó, odds được định nghĩa bằng:
Như vậy, nếu odds > 1, khả năng mắc bệnh cao hơn khả năng không mắc bệnh; nếu odds = 1 thì điều này cũng có nghĩa là khả năng bằng với khả năng không mắc bệnh; và nếu odds < 1, chúng ta có thể nói khả năng mắc bệnh thấp hơn khả năng không mắc bệnh.
Với định nghĩa này, chúng ta quay lại với ví dụ vừa trình bày về RR. Odds mắc bệnh trong nhóm được điều trị (kí hiệu odds1) và nhóm chứng (kí hiệu odds2) là:

Mối liên hệ giữa RR và OR. Qua công thức [1] và [2], chúng ta có thể thấy OR và RR có một mối liên hệ số học. Có thể viết lại công thức RR như là một hàm số của OR (hay ngược lại), nhưng ở đây, tôi chỉ muốn lưu ý một điểm quan trọng có liên quan đến việc diễn dịch RR và OR.
Nhìn vào công thức định nghĩa odds, chúng ta dễ dàng thấy nếu tỉ lệ mắc bệnh p thấp (chẳng hạn như 0.001 hay 0.01 – tức 0.1% hay 1%), thì odds≈p![]() . Chẳng hạn như nếu p = 0.01, thì 1 – p = 0.99, và do đó odds = 0.01 / 0.99 = 0.010101, tức rất gần với p = 0.01. Quay lại với công thức [2], nếu nguy cơ mắc bệnh (p1 hay p2) (
. Chẳng hạn như nếu p = 0.01, thì 1 – p = 0.99, và do đó odds = 0.01 / 0.99 = 0.010101, tức rất gần với p = 0.01. Quay lại với công thức [2], nếu nguy cơ mắc bệnh (p1 hay p2) (![]() hay
hay ![]() ) thấp hay rất thấp, thì OR có thể viết như sau:
) thấp hay rất thấp, thì OR có thể viết như sau:
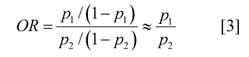
Nói cách khác, nếu nguy cơ mắc bệnh thấp, thì OR gần bằng với RR. Nhưng nếu nguy cơ mắc bệnh cao (chẳng hạn như trên 10%) thì chỉ số OR cũng cao hơn chỉ số RR.
Có thể làm một vài tính toán để thấy sự khác biệt giữa RR và OR qua bảng số liệu sau đây (Bảng 1). Với những trường hợp nguy cơ mắc bệnh dưới 5%, OR và RR không khác nhau đáng kể. Nhưng nếu nguy cơ mắc bệnh cao hơn 10%, thì OR thường ước tính RR cao hơn thực tế.
Bảng 1. So sánh RR và OR với nhiều tỉ lệ khác nhau (số liệu mô phỏng)
|
Trường hợp |
Tỉ lệ (nguy cơ) mắc bệnh |
Odds mắc bệnh |
So sánh giữa RR và OR |
|||
|
Nhóm 1 (p1) |
Nhóm 2 (p2) |
Nhóm 1 (odds1) |
Nhóm 2 (odds2) |
RR |
OR |
|
|
1 |
0.001 |
0.003 |
0.002 |
0.003 |
3 |
3.01 |
|
2 |
0 |
0.03 |
0.01 |
0.03 |
3 |
3.06 |
|
3 |
0.02 |
0.06 |
0.02 |
0.06 |
3 |
3.13 |
|
4 |
0.05 |
0.15 |
0.05 |
0.18 |
3 |
3.35 |
|
5 |
0.10 |
0.30 |
0.11 |
0.43 |
3 |
3.86 |
|
6 |
0.15 |
0.45 |
0.18 |
0.82 |
3 |
4.64 |
|
7 |
0.20 |
0.60 |
0.25 |
1.50 |
3 |
6.00 |
|
8 |
0.25 |
0.75 |
0.33 |
3.00 |
3 |
9.00 |
|
9 |
0.30 |
0.90 |
0.43 |
9.00 |
3 |
21.0 |
|
10 |
0.33 |
0.99 |
0.49 |
99.0 |
3 |
2101.0 |
Chú ý: Bảng trên đây được mô phỏng sao cho RR = 3 để chứng minh rằng OR ước tính độ ảnh hưởng cao hơn so với thực tế.
RR và OR: ứng dụng
Ví dụ 1: truy tìm ung thư vú. Chương trình truy tìm ung thư vú được khuyến khích như là một phương cách y tế công cộng nhằm giảm nguy cơ tử vong từ bệnh này ở phụ nữ. Một nhóm nghiên cứu ở Thụy Điển tiến hành một nghiên cứu lâm sàng đối chứng ngẫu nhiên (RCT), mà trong đó họ tuyển các phụ nữ tuổi 50 trở lên, và chia thành 2 nhóm: nhóm A gồm 66103 phụ nữ được chụp mammography thường xuyên (mỗi năm một lần), và nhóm B gồm 66105 phụ nữ không chụp mammography mà chỉ theo dõi bình thường (tức nhóm chứng). Sau 5 năm, nhóm A có 183 người tử vong vì ung thư vú và nhóm B có 177 người tử vong. Số liệu được trình bày trong Bảng 2 sau đây:
Bảng 2: Truy tìm ung thư vú và tử vong
|
Nhóm |
Tổng số đối tượng tham gia |
Số tử vong |
|
A – Mammography |
66,103 |
183 |
|
B – Nhóm chứng |
66,105 |
177 |
Với số liệu này, chúng ta có thể thấy nguy cơ tử vong trong nhóm A là PA = 183/66103 = 0.002768 ![]() và nhóm B là PA = 177/66105 = 0.002678
và nhóm B là PA = 177/66105 = 0.002678![]() . Từ đó, RR có thể ước tính bằng công thức [1] như sau:
. Từ đó, RR có thể ước tính bằng công thức [1] như sau:

Như vậy, OR bằng RR. Nhưng cách diễn dịch của OR khác với RR. Bởi vì đơn vị của RR là nguy cơ tử vong, cho nên chúng ta có thể nói rằng nhóm chụp mammography thường xuyên có nguy cơ tử vong cao hơn nhóm đối chứng khoảng 3.4%. Nhưng đơn vị của OR là odds, cho nên chúng ta không thể phát biểu về “nguy cơ tử vong”, mà chỉ có thể phát biểu rằng “khả năng” hay odds tử vong của nhóm A cao hơn nhóm B khoảng 3.4%. Ở đây, vì nguy cơ tử vong thấp, cho nên như công thức [3] cho thấy hai chỉ số này giống nhau, và trong thực tế chúng ta có thể diễn dịch một OR như là RR.
Cách phân biệt trên có vẻ máy móc và lí thuyết, nhưng quan trọng. Để thấy rõ nguy hiểm trong cách diễn dịch OR, tôi sẽ trình bày một ví dụ sau đây:
Ví dụ 2: sắc tộc và tỉ lệ thông tim (cardiac catherization). Tập san New England Journal of Medicine số ra ngày 25/2/1999 (tập 349; trang 618-626) công bố một nghiên cứu rất thú vị về ảnh hưởng của sắc tộc đến tỉ lệ thông tim. Trong nghiên cứu này, các nhà nghiên cứu mướn một số diễn viên điện ảnh người da trắng và da đen đóng vai bệnh nhân. Các diễn viên được chỉ cách trình bày các triệu chứng và bệnh trạng cẩn thận và đầy đủ, nhưng giống nhau. Họ thu hình các diễn viên vào video; chọn ngẫu nhiên 720 bác sĩ chuyên khoa tim người da trắng, cho họ xem các video này, và hỏi “ai cần được thông tim”. Kết quả cho thấy 90.6% bác sĩ đề nghị các bệnh nhân da trắng nên được thông tim, nhưng tỉ lệ này cho bệnh nhân da đen chỉ 84.7%. Một phần của kết quả có thể tóm lược trong Bảng 3 sau đây:
Bảng 3: Sắc tộc và tỉ lệ thông tim
|
Nhóm |
Số bác sĩ đề nghị thông tim |
Số bác sĩ không đề nghị thông tim |
|
w – Bệnh nhân da trắng |
652 |
68 |
|
b – Bệnh nhân da đen |
610 |
110 |
Các nhà nghiên cứu kết luận rằng tỉ lệ bệnh nhân da đen được thông tim thấp hơn tỉ lệ ở bệnh nhân da trắng đến 40%. Sau khi nghiên cứu này công bố, giới truyền thông rầm rộ bàn về kết quả và ý nghĩa của nghiên cứu. Không cần nói ra, cũng có thể đoán được trong dư âm và tình trạng kì thị chủng tộc ở Mĩ còn kéo dài, những nhóm đấu tranh chống kì thị chủng tộc lấy kết quả này để làm bằng chứng tố cáo rằng các bác sĩ da trắng kì thị bệnh nhân da đen. Ý nghĩa còn sâu xa hơn: sự kì thị này có thể dẫn đến tử vong. Nói cách khác, có người diễn dịch rằng đây là một sự cố sát!
Nhưng rất tiếc là con số 40% đó đã được diễn dịch cực kì sai. Không những diễn dịch sai mà cách tính toán cũng sai. Để hiểu tại sao cách diễn dịch đó sai, chúng ta hãy bắt đầu bằng cách tính OR của các tác giả. Odds thông tim trong nhóm bệnh nhân da trắng là:

Tại sao có sự khác biệt? Tại vì các tác giả và giới truyền thông nhầm lẫn rằng OR là RR. Trong trường hợp này, OR không phải là một chỉ số thích hợp để phân tích số liệu, bởi vì son số tỉ lệ quá cao (84.7% và 90.6%), và vì tỉ lệ quá cao, cho nên OR ước tính RR quá cao hơn thực tế.
Thật ra, ở đây cách gọi “RR” cũng không chính xác. RR chỉ sử dụng cho tỉ lệ phát sinh (incidence), nhưng trong trường hợp này không có tỉ lệ phát sinh, mà là tỉ lệ lưu hành (prevalence). Do đó, thuật ngữ chính xác để mô tả 0.935 là prevalence ratio (PR). (Đây là một đề tài khác mà tôi hi vọng sẽ có dịp quay lại để bàn thêm). Điều ngạc nhiên là sai sót này lại hiện diện ngay trên giấy trắng mực đen của một tập san y học vào hàng số 1 trên thế giới!
Vấn đề diễn dịch OR
RR là tỉ số của 2 tỉ lệ hay 2 nguy cơ, và tỉ lệ thì chúng ta có thể hiểu được khá dễ dàng. Nếu nói tỉ lệ mắc bệnh 3%, chúng ta nghĩ ngay đến 3 trong 100 người mắc bệnh. Vì thế, vấn đề diễn dịch RR khá dễ dàng. Nếu RR = 2, chúng ta có thể nói rằng tỉ lệ tăng gấp 2 lần. Ai
cũng hiểu được mà không chất vấn gì thêm.
OR là tỉ số của hai odds. Odds phản ảnh “khả năng” mắc bệnh. Odds = 2 có nghĩa là khả năng mắc bệnh cao hơn khả năng không mắc bệnh 2 lần. Khó hiểu. Odds đã khó hiểu thì tỉ số của hai odds (hay hai khả năng) lại càng là một đo lường khó hiểu hơn vì nó quá chung chung, khó cảm nhận được. Thật ra, một người bình thường khó có thể hiểu chính xác nghĩa của OR. Chúng ta biết OR = 2 không hẳn có cùng nghĩa với RR = 2. Chính vì thế mà gần đây có “phong trào xét lại” OR trên các tập san y học quốc tế. Nhiều nhà nghiên cứu, dịch tễ học và thống kê học kêu gọi bỏ OR!
Nhưng bất cứ đo lường nào cũng lợi thế và khiếm khuyết. RR, dù dễ diễn dịch cũng có khiếm khuyết của nó. Lấy ví dụ đơn giản: nếu tỉ lệ mắc bệnh ung thư trong nhóm A là 1% và nhóm B là 3%, chúng ta dễ dàng thấy RR = 3. Nhưng thay vì nói mắc bệnh, chúng ta lật ngược lại vấn đề “không mắc bệnh”: chúng ta có tỉ lệ cho nhóm A là 99% so với nhóm B là 97%, và như thế RR = 0.97 / 0.99 = 0.98, tức là tỉ lệ không mắc bệnh trong nhóm B thấp hơn nhóm A khoảng 2%. (Nhưng nếu dùng “mắc bệnh”, nhóm A mắc bệnh nhiều hơn nhóm B đến 3 lần!) Nói cách khác, RR có thể thiếu tính nhất quán (consistency).
Nhưng OR thì nhất quán. Trong ví dụ trên, nếu lấy chỉ số là “mắc bệnh” làm so sánh, OR là 3.06. Nhưng nếu lấy “không mắc bệnh” làm chỉ số son sánh, thì OR vẫn là 3.06 (bạn đọc có thể kiểm tra con số này). Trong toán thống kê, người ta gọi đặc tính của OR là symmetric (đối xứng), còn đặc tính của RR là asymmetric (bất đối xứng).
OR, PR, RR và thể loại nghiên cứu
Một khác biệt cơ bản nữa giữa RR và OR là sự tùy thuộc vào thể loại nghiên cứu. Nói một cách ngắn gọn, RR chỉ có thể ước tính từ nghiên cứu xuôi thời gian (cohort prospective study), nhưng OR thì có thể ước tính từ tất cả thể loại nghiên cứu, nhưng chủ yếu là nghiên cứu bệnh – chứng.
Bởi vì OR có thể sử dụng cho nghiên cứu cắt ngang nhưng có vấn đề về diễn giải, và nghiên cứu cắt ngang chỉ có thể ước tính prevalence hay tỉ lệ lưu hành, nên các nhà nghiên cứu đề nghị sử dụng prevalence ratio (PR) thay cho OR đối với các nghiên cứu cắt ngang. Tương tự như RR là tỉ số của hai incidence (tỉ lệ phát sinh), PR là tỉ số của 2 tỉ lệ lưu hành.
Một chỉ số khác cũng có ý nghĩa tương tự như ralative risk là hazard ratio (HR hay tỉ số rủi ro). Thông thường các nghiên cứu lâm sàng theo dõi đối tượng trong một thời gian dài, thay vì tính tỉ lệ phát sinh bệnh trong thời gian đó, thỉnh thoảng các nhà nghiên cứu tính tỉ lệ phát sinh tích lũy (cumulative risk) trong thời gian cho từng nhóm, và tính HR. Tuy cách tính này, đứng trên phương diện toán học, chính xác hơn cách tính tỉ lệ trên 100 người-năm hay trên 100 đối tượng, nhưng trong thực tế thì HR và RR không khác nhau đáng kể. Trong trường hợp thời gian theo dõi giữa 2 nhóm tương đương nhau thì hầu như không có khác biệt nào giữa RR và HR.
Bảng 4: Thể loại nghiên cứu và sự thích hợp của OR, PR, RR
|
Thể loại nghiên cứu (Study design) |
Chỉ số thống kê |
Mô hình phân tích |
|
Bệnh chứng (case-control) |
Odds ratio (OR) |
Hồi qui logistic (logistic regression) |
|
Cắt ngang (cross-sectional) |
Prevalence ratio (PR) hay OR |
Hồi qui nhị phân (binomial regression) hay Hồi qui logistic |
|
Theo thời gian (prospective) |
Relative risk (RR) |
Hồi qui Cox (Cox’s regression model) |
|
Thử nghiệm lâm sàng RCT |
RR hay Hazard ratio (HR) |
Hồi qui Cox |
Giả dụ chúng ta muốn tìm hiểu mối liên hệ giữa phơi nhiễm chất độc màu da cam (Agent Orange – AO) và bệnh ung thư. Một cách nghiên cứu qui mô là tuyển chọn [ngẫu nhiên] một nhóm đối tượng, sau đó phân nhóm dựa vào tiền sử có bị phơi nhiễm độc chất hay không. Sau đó, theo dõi cả hai nhóm đối tượng một thời gian (chẳng hạn như 5 năm) và ghi nhận số người bị ung thư. Kết quả của nghiên cứu như thế có thể tóm lược trong Bảng 5 sau đây. Trong số 1000 người được thẩm định bị phơi nhiễm lúc ban đầu, có 20 người (hay 2%) bị ung thư trong thời gian theo dõi; trong số 10,000 người không bị phơi nhiễm AO, có 100 người (tức 1%) bị ung thư sau đó. Như vậy, RR = 0.02/0.01 = 2. Nhưng nếu tính bằng odd thì OR = 2.02. Hai chỉ số này không khác nhau đáng kể.
Bảng 5. Một nghiên cứu xuôi thời gian (giả tưởng)
|
Nhóm |
Ung thư |
Không ung thư |
Tổng số |
|
Phơi nhiễm AO |
20 |
980 |
1000 |
|
Không phơi nhiểm AO |
100 |
9900 |
10000 |
Nhưng theo dõi đối tượng một thời gian dài thường rất tốn kém. Một phương pháp nghiên cứu khác cũng có thể đáp ứng mục đích tìm hiểu mối liên hệ giữa AO và ung thư, nhưng cần ít đối tượng hơn và không cần theo dõi một thời gian dài: đó là nghiên cứu bệnh – chứng. Bảng 6 dưới đây trình bày kết quả một nghiên cứu (giả tưởng) như thế. Trong nghiên cứu này, chúng ta chọn 100 bệnh nhân ung thư và 100 đối tượng không bị ung thư, nhưng hai nhóm này tương đương nhau về các yếu tố nguy cơ. Sau đó, chúng ta tìm hiểu qua hồ sơ bệnh lí (hay phỏng vấn) trong mỗi nhóm có bao nhiêu người bị phơi nhiễm độc chất. Nói cách khác, đây là một nghiên cứu “ngược thời gian” (so với nghiên cứu “xuôi thời gian” như trình bày trong Bảng 4. Kết quả nghiên cứu bệnh chứng này được trình bày như sau:
Bảng 6. Một nghiên cứu bệnh – chứng (giả tưởng)
|
Nhóm |
Ung thư |
Không ung thư |
|
Phơi nhiễm AO |
10 |
5 |
|
Không phơi nhiểm AO |
90 |
95 |
|
Tổng số |
100 |
100 |
Trong nhóm bệnh nhân, có 10 người (hay 10%) từng bị phơi nhiễm AO; và trong nhóm không ung thư số đối tượng từng bị phơi nhiễm là 5 người (hay 5%). Ở đây, chúng ta không thể tính tỉ lệ phát sinh bệnh (incidence), bởi vì số lượng bệnh nhân và đối chứng đã được xác định trước. Vì không thể ước tính tỉ lệ phát sinh, nghiên cứu bệnh chứng không cho phép chúng ta ước tính RR. Tuy nhiên, chúng ta có thể tính OR, và OR trong trường hợp này là một ước tính chỉ số RR.
Số liệu Bảng 6 cho thấy odds bị phơi nhiễm trong nhóm bệnh nhân là: 10/90 = 0.1111, và nhóm đối chứng: 0.05263. Do đó, OR = 0.1111 / 0.05263 = 2.11. Thật ra, có thể tính đơn giản hơn bằng công thức “giao chéo”:
![]()
Điểm chính để phân biệt hai hình thức nghiên cứu này là phương pháp chọn mẫu. Với nghiên cứu xuôi thời gian, chúng ta xác định số lượng đối tượng theo yếu tố nguy cơ ngay từ đầu, và số lượng bệnh phát sinh là một số ghi nhận. Ngược lại, với nghiên cứu ngược thời gian, chúng ta xác định số lượng bệnh nhân và đối tượng ngay từ đầu, và số lượng phơi nhiễm yếu tố nguy cơ là số ghi nhận.
Tuy kết quả nghiên cứu của hai thể loại nghiên cứu được trình bày rất giống nhau: hai cột và hai dòng (2×2 table), nhưng “câu chuyện” đằng sau của các số liệu này rất khác nhau. Không am hiểu câu chuyện đằng sau của một bảng số liệu rất dễ dàng sai lầm trong khi phân tích!
Tóm tắt
Tóm lại, cả hai RR và OR đều là những chỉ số phản ảnh độ tương quan giữa một yếu tố nguy cơ và bệnh; nhưng RR mới là chỉ số chúng ta cần biết (còn OR chỉ là ước số của RR). Cần phải xác định rằng odds không phải là risk hay nguy cơ. Do đó, ý nghĩa của OR rất khó diễn giải. Đây chính là lí do mà một số nhà nghiên cứu đòi “tẩy chai” OR [1,2]. Nhưng vì tính nhất quán của OR so với RR nên việc sử dụng OR cần phải đặt vào bối cảnh nghiên cứu [3]. Trong nghiên cứu cắt ngang hay nghiên cứu theo thời gian, và khi tỉ lệ lưu hành hay tỉ lệ phát sinh bệnh cao thì nên tránh sử dụng OR [4].
Việc chọn OR và RR tùy theo mô hình nghiên cứu [5-7]. OR có thể sử dụng cho tất cả các nghiên cứu bệnh chứng (case-control study), cắt ngang (cross-sectional study), nghiên cứu theo dõi bệnh nhân theo thời gian (prospective study) kể cả nghiên cứu lâm sàng đối chứng ngẫu nhiên (RCT). RR chỉ có thể sử dụng cho các nghiên cứu theo dõi bệnh nhân theo thời gian và nghiên cứu lâm sàng đối chứng ngẫu nhiên. Đối với các nghiên cứu cắt ngang, PR thường được sử dụng để khắc phục những khó khăn trong diễn giải OR.
Về mặt tính toán, không có gì sai khi một nghiên cứu cắt ngang hay theo thời gian sử dụng OR. Nhưng cần phải hết sức cẩn thận khi diễn giải OR trong các nghiên cứu cắt ngang, vì OR tùy thuộc vào nguy cơ mắc bệnh (và khi nguy cơ mắc bệnh cao – như trên 10% – thì OR thường cao hơn so với thực tế). Do đó, các nghiên cứu cắt ngang ngày nay thường sử dụng prevalence ratio.
Quay trở lại bài
báo mà người viết bài này bình duyệt, khi tác giả viết: “The risk of fracture in the CC genotype was 45% lower than TT group (OR = 0.55; 95% CI: 0.32 – 0.94; P = 0.03)“, họ nhầm lẫn giữa khái niệm nguy cơ và odds. Cách diễn giải đúng là “The odds of fracture in the CC genotype was 45% lower than TT group” (Nhóm với biến thể gene CC có nguy cơ gãy xương thấp hơn 45% so với nhóm với biến thể TT).
Tài liệu tham khảo
1. Sackett DL, Deeks JJ, Altman DG. Down with odds ratios! Evidence-Based Med 1996; 1: 164-166.
2. Deeks J. When can odds ratios mislead? Odds ratios should be used only in case-control studies and logistic regression analyses [letter]. British Medical Journal 1998:317(7166);1155-6; discussion 1156-7.
3. Altman DG, Deeks JJ, Sackett DL. Odds ratios should be avoided when events are common. British Medical Journal 1998;317:1318.
4. Schmidt CO, Kohlmann T. When to use the odds ratio or the relative risk? International Journal of Public Health 2008; 53:165-7.
5. Fahey T, Griffiths S and Peters TJ. Evidence-based purchasing: understanding results of clinical trials and systematic reviews. British Medical Journal 1995:311(7012);1056-9; discussion 1059-60.
6. Greenland S. Interpretation and Choice of Effect Measures in Epidemiologic Analyses. American Journal of Epidemiology 1987:125(5);761-767.
7. Pearce N. What Does the Odds Ratio Estimate in a Case-Control Study? International Journal of Epidemiology 1993:22(6);118


{kind=link}